
Attention is all you need 阅读
Attention is all you need 阅读
Ivoripuion一个应用场景:Attention is all you need提出来的Transformer模型最经典的案例就是翻译以及当下最火的生成式语言。
传统的RNN等神经网络模型都是编码器-解码器的结构:
- 编码器:将输入$(x_1,x_2,…,x_n)$转换成向量数组$(z_1,z_2,…,z_n)$,其中每个$z_t$对应于一个词$x_t$的向量表示。这里编码器的输出就是这么一个向量数组。
- 解码器:将编码器输出的数组$(z_1,z_2,…,z_n)$解码为一个序列$(y_1,y_2,…,y_m)$,这里的m并一定等于n,因为假如中译英,输入句子和输出句子长度往往是不一样的。这里解码器输出的词是一个一个生成的——自回归,比如$y_i$的输出往往会依赖于$y_{i-1}$。
具体模块
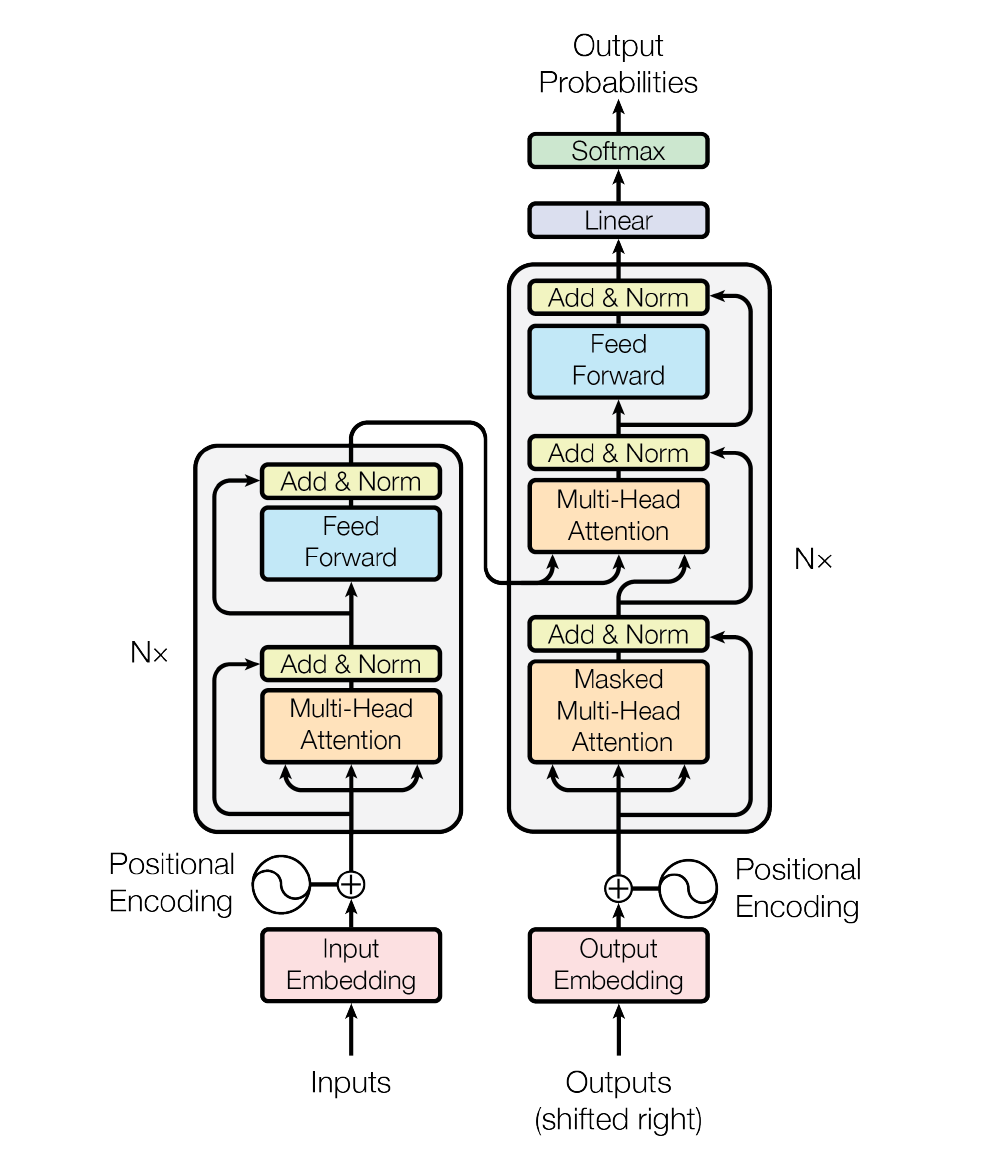
Transformer图里各个模块的含义:
- 左侧:编码器
- 右侧:解码器
- Input:编码器的输入,比如需要翻译的句子
- Output:解码器的输入,也就是解码器之前状态的输出
- Input Embedded:嵌入层,将各个词表示成向量
- N*:表示编码器有n个
- Multi-head Attetion:多头注意力层
- Feed Forward:MLP层,用于拟合特征和目标之间真实函数的关系
- Masked Muti-Head Attention:相比于编码器多的一个部分,保证训练和预测的行为是一致的
有关Layer Norm:
- batch norm:在每一个特征矩阵mini-norm(列)里,将均值变成0,方差变成1(向量减掉均值再除以方差)
- layer norm:对每个样本做类似的操作(行),将其变成均值为0方差为1
子层
注意力
注意力就是:给一个query,去看它跟key的相似度,然后根据这个相似度计算所需要的value的权重。这里虽然key、value都一样,但是因为query和key的相似度不同得到的输出也不同,这里的相似度就是注意力。
transformer这里主要先计算key、query(维度都是$d_k$)的内积,然后除以$\sqrt{d_k}$,然后放入$softmax$将这个向量变成非负数和加起来等于1,最后乘以value。
两种常见的注意力机制:
- 加型注意力:处理key、query不等的情况
- 点积注意力:就是没有除以$\sqrt{d_k}$的样子
这里用的是点积注意力机制。
Mask机制
Mask是为了避免在第t时间看到后面的东西,只关心生成之前的键值对。
举个例子:我们在query $q_t$只想看到$k_1$到$k_{t-1}$,此时用一个Mask,将$(k_t,k_{t+1},…,k_n)$的值都换成一个大的负数,这些负数进入softmax做运算(指数运算)的时候都会变成0,于是当我们算output的时候,我们其实只关注了$(v_1,…,v_{t-1})$的value。
muti-head
之前的注意力机制的地方只学了点积的内容,使用多头之后可以学习到更多的东西(就像在卷积网络有多个输出通道)。
具体来说,会将多个head concat起来再投影到一个$W^o$里面。
就像让8个不同专业的专家同时分析句子:
- 语法专家关注词性搭配
- 语义专家分析含义关联
- 语境专家把握上下文关系
最后把8位专家的结论拼接起来,获得更全面的理解。









